
Computers, at their core, do math. Mathematical calculations are done numerically. So, for this computers can process any non-numerical data such as text or images, they must first be converted to digital form.
Embedding is a vector representation of the data. As a general rule, embeddings are data that has been transformed into N-dimensional matrices. A word embedding is a vector representation of words.

What are Vectors?
In physics and mathematics, a vector is an object that has a magnitude and a direction, like an arrow in space. The length of the arrow is the magnitude of the quantity and the direction that the arrow points to is the direction of the quantity. Examples of such quantities in physics are velocity, force, acceleration etc. In computer science and machine learning, the idea of a vector is an abstract representation of data, and the representation is an array or list of numbers. These numbers represent the features or attribute of the data. In NLP, a vector can represent a document, a sentence or even a word. The length of the array or list is the number of dimensions in the vector. A two dimensional vector will have two numbers, a three-dimensional vector has three numbers, and an n-dimensional vector will have ‘n’ numbers.
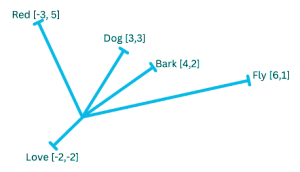
Unidimensional Vectors

Dog = 1, Bark = 2 and Fly = 6 then Love=?
Unidimensional vectors are not great representations because unrelated words cannot be plotted accurately?
More Dimensions, Better Context
The goal of an embedding model is to covert words (or sentences/paragraphs) into ndimensional vectors, such that the words (or sentences/paragraphs) that are like each other in meaning, lie close to each other in the vector space
An embeddings model can be trained on a corpus of preprocessed text data using an embedding algorithm like Word2Vec, GloVe, FastText or BERT.
Training a custom embeddings model can prove to be beneficial in some use cases where the scope is limited. Training an embeddings model that generalizes well can be a laborious exercise. Collection and pre-processing text data can be cumbersome. The training process can turn out to be computationally expensive too.
Famous pre-trained Embeddings
The good news for anyone building RAG enabled systems is that embeddings once created can also generalize across tasks and domains.
1. Embeddings Models by OpenAI
OpenAI, the company behind ChatGPT and GPT series of Large Language Models also provide three Embeddings Models : textembedding-ada-002, text-embedding-3-small, text-embedding-3-large OpenAI models can be accessed using the OpenAI API
2. Gemini Embeddings Model by Google
text-embedding-004 (last updated in April 2024) is the model offered by Google Gemini. It can be accessed via the Gemini API
3. Voyage AI
Voyage AI embeddings models are recommended by Anthropic, the providers of Claude series of Large Language Models. Voyage offers several embeddings models like voyage-large-2-instruct, voyage-law-2, voyage-code-2
4. Mistral AI Embeddings
Mistral is the company behind LLMs like Mistral and Mixtral. They offer a 1024-dimension embeddings model by the name of mistral-embed. This is an open-source embeddings model.
5. Cohere Embeddings
Cohere, the developers of Command, Command R and Command R+ LLMs also offer a variety of embeddings models like embed-englishv3.0, embed-english-light-v3.0, embed-multilingual-v3.0, etc. and can be accessed via cohere API.
Famous pre-trained Embeddings
The good news for anyone building RAG enabled systems is that embeddings once created can also generalize across tasks and domains.
These five models are in no way recommendations but just a list of the popular embeddings models. Apart from these providers, almost all LLM developers like Meta, TII, LMSYS also offer pre-trained embeddings models
Embeddings Use Cases
The reason why embeddings are popular is because they help in establishing semantic relationship between words, phrases, and documents. In the simplest methods of searching or text matching, we use keywords and if the keywords match, we can show the matching documents as results of the search. However, this approach fails to consider the semantic relationships or the meanings of the words while searching. This challenge is overcome by using embeddings.
Text Search: Embeddings are used to calculate similarity between the user query and the stored documents.
Clustering: Embeddings are used to group similar pieces of text together to find out, for example, the common themes in customer reviews.
Machine Learning: Advanced machine learning techniques can be used for different problems like classification and regression. To convert text data into numerical features, embeddings prove to be a valuable technique.
Recommendation Engines: Shorter distances between product features means greater similarity. Using embeddings for product and user features can be used to recommend similar products.
#ref-MEAP social blogs





